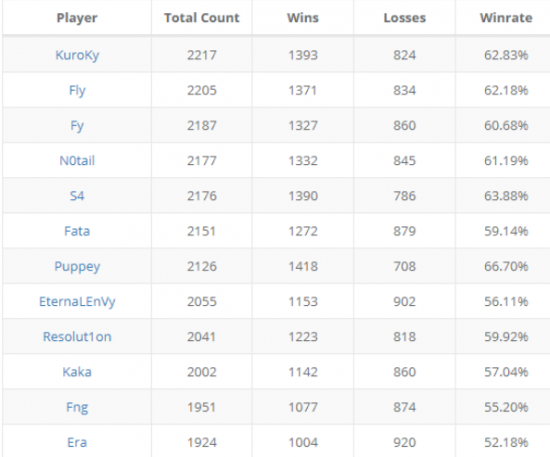
2025-12-28 23:48:50
/asset/images/17669657303210.png
近年来,人工智能领域的研究不断推进,各大高校和研究机构积极探索新的方法,以提高模型的推理能力。复旦大学的研究团队近期提出了一种创新的思路,通过游戏机制来增强VLM通用推理能力,取得了令人瞩目的成果。
复旦大学的创新研究
复旦大学的研究者们发现,传统的推理模型在处理复杂数据时往往显得力不从心。为了解决这一问题,他们设计了一种基于游戏的训练机制,旨在通过模拟真实世界中的决策过程来提升模型的推理能力。
游戏机制的优势
游戏机制不仅具有趣味性,还能够通过互动的方式帮助模型学习。在这种机制下,模型需要在动态环境中进行决策,面对不断变化的挑战。这种训练方式使得模型能够更好地适应复杂的推理任务,从而在实际应用中表现出色。
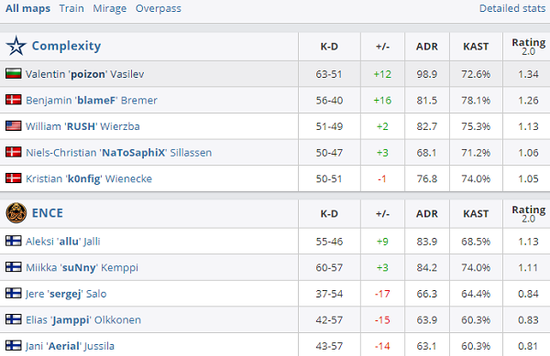
与几何数据的比较
研究结果表明,采用游戏机制训练的VLM模型,其通用推理能力与基于几何数据的传统模型相当。这一发现为人工智能推理模型的设计提供了新的思路,也为未来的研究指明了方向。
未来的展望
随着人工智能技术的不断发展,如何提高模型的推理能力已成为一个亟待解决的问题。复旦大学的这一创新研究不仅为VLM模型的发展提供了新路径,也为其他领域的研究者提供了参考。未来,我们期待看到更多基于游戏机制的创新应用,推动人工智能技术的进一步发展。
